Alex Ziskind's latest video carries a headline that does its job: "AMD's Strix Successor Just Caught the M4 Pro." And on one benchmark, it genuinely did. But the machine in the video, the Beelink SER10 Max, built on AMD's brand-new Ryzen AI 9 HX 470 "Gorgon Point" chip, is a more interesting and more cautionary buy than the title suggests, especially if you're shopping it to run local LLMs. We haven't tested one; what follows summarizes Ziskind's measured results and grounds them in primary specs and the wider local-AI picture.
First, the name games: this is Strix Point's successor, not Strix Halo's
This matters more than it sounds. The local-AI crowd has spent 2026 obsessing over Strix Halo, the Ryzen AI Max+ 395, with its 256-bit memory bus and up to 128 GB of unified memory. The chip in the Beelink SER10 Max is not that. It's Gorgon Point, a mid-cycle refresh of the smaller Strix Point laptop platform. Per AMD's own spec sheet, the Ryzen AI 9 HX 470 is a 12-core part (4 Zen 5 + 8 Zen 5c) boosting to ~5.2 GHz, paired with the same Radeon 890M iGPU (16 RDNA 3.5 compute units) and a 55-TOPS XDNA 2 NPU that the year-old SER9 already had. Independent coverage confirms Gorgon Point is exactly that, a clock-and-polish refresh on Strix Point's bones, not a new architecture.
So set expectations accordingly: this is a capable thin-and-light-class mini PC, not a 70B-model machine. The SER10 Max ships with 32 or 64 GB (a 96 GB/2 TB config exists for around $2,300), and about half the memory can be carved out for the iGPU, Ziskind's 64 GB unit exposed ~29 GB as graphics memory.
The CPU story: one big leap, mostly flat, and a Geekbench number worth double-checking
Ziskind's developer suite tells a split-screen story. On the V8 Web Tooling benchmark (a real TypeScript/Babel/Terser toolchain), the SER10 jumped from the SER9's ~20 to 34.14 on the TypeScript score, a ~65% generational gain that lands it within 5% of both the base M4 and M4 Pro Mac minis (~35.99). That's the "caught the Mac" moment, and it's real.
Everywhere else, it's flat. His all-core Python test: SER9 28.64s vs SER10 28.9s, a quarter-second apart, i.e. the same. His synthetic .NET compile: SER9 ~91s vs SER10 ~90.9s, again, identical. On the real-world Umbraco.NET build, the SER10 came in slightly slower (161s) than the SER9 (149s). None of that is a knock on the chip so much as physics: same iGPU, same core count, mild clock bump.
One number deserves a flag. The video's chart shows the M4 Pro at ~15,321 Geekbench 6 multi-core, and a sharp commenter (@charlievarley) caught that this looks like a base-M4 score, not an M4 Pro one. They're right: Geekbench's published Mac mini M4 Pro (14-core) average is ~3,821 single / ~22,430 multi across 5,000+ results. Using the correct figure, the multi-core gap between these mini PCs and the M4 Pro is far wider than the video's chart implied, the M4 Pro stays comfortably ahead on heavy compiles, which matches the Umbraco result. Worth knowing before you read "caught the M4 Pro" as a multi-core claim.
The local-LLM story: your AI runs on the wrong chip by default
Here's the part that earns this box a place on a local-AI site. The SER10 has three things that can run a model, CPU, the Radeon 890M iGPU, and the XDNA 2 NPU, and out of the box on Windows, Ollama uses the CPU. Ziskind ran Qwen 2.5 7B and watched the CPU peg while the GPU and NPU sat idle, landing a sluggish 14.2 tok/s. This isn't a one-off: AMD's own GAIA bug tracker (issue #1295) documents the same "appears CPU-bound / not GPU-accelerated by default" behavior on Strix-class parts.
The fix is a single environment flag. Setting OLLAMA_VULKAN=true moves inference onto the iGPU via llama.cpp's Vulkan backend, necessary because ROCm still doesn't support these RDNA 3.5 iGPUs (gfx1150) on Windows, so Vulkan is the real path. Flip it, and Ziskind's numbers jumped: Llama 3.2 3B went 27 → 37.5 tok/s, Qwen 2.5 1.5B went 47.5 → 68.3 tok/s. (If you want the click-by-click, this Vulkan-for-Ollama walkthrough covers it.)
The NPU is the wildcard everyone asks about and nobody benchmarks. Using AMD's Lemonade Server, an OpenAI-compatible local server that routes prefill to the NPU and decode to the iGPU, Ziskind got ~14.3 tok/s on a 1B model. The theory is sound: prefill (prompt processing) is compute-bound and the NPU cuts time-to-first-token roughly in half, while decode is memory-bound and better left to the GPU. In practice today it's promising plumbing, not a reason to buy.
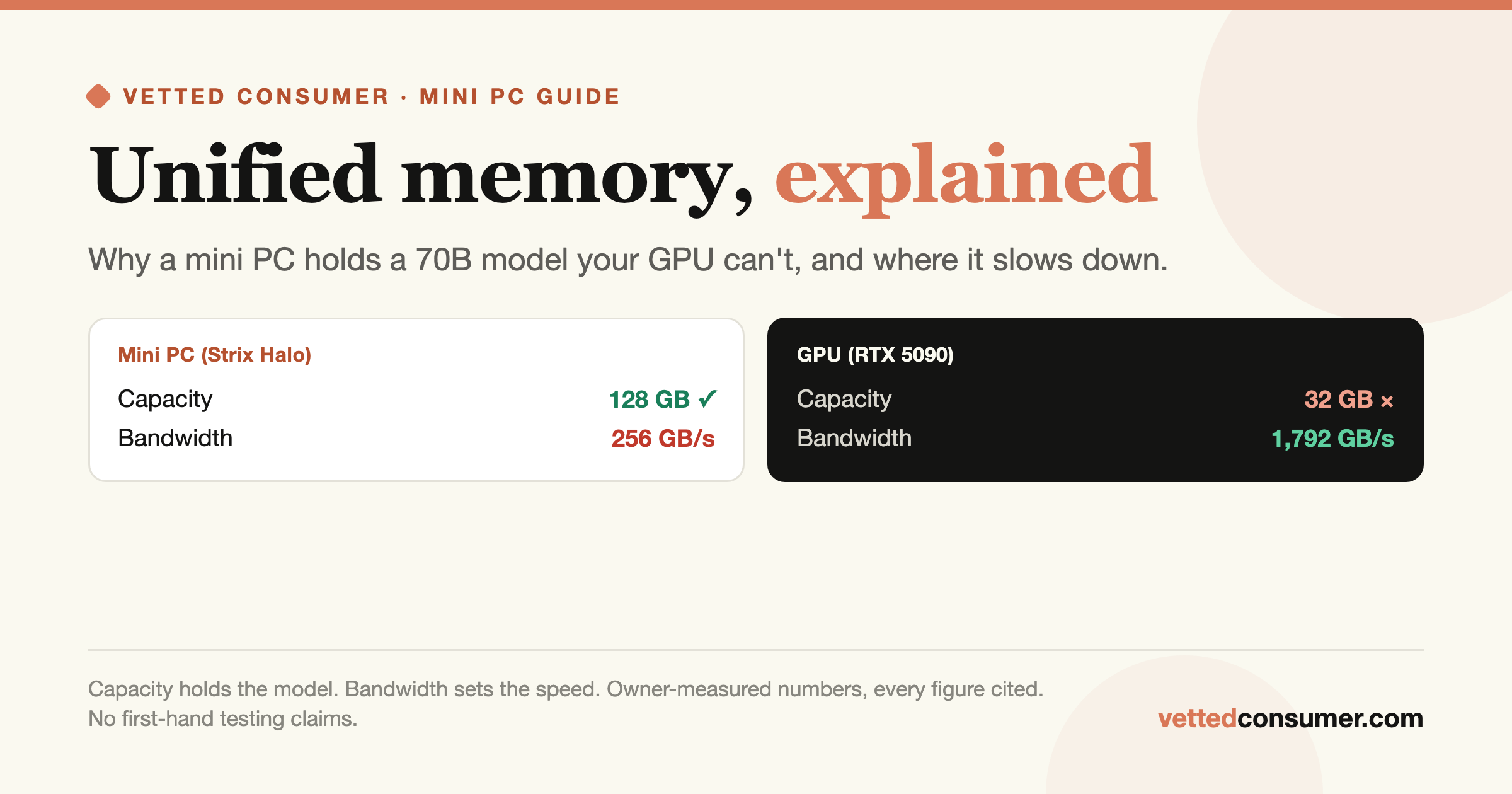
The number that should drive your decision: memory bandwidth
Token generation is memory-bandwidth-bound, every token requires reading the model's weights out of RAM, so for local LLMs, bandwidth predicts speed better than any CPU score. And this is where the "successor" gets awkward:
- SER10 Max, DDR5-5600 (SODIMM, upgradeable): ~90 GB/s. Ziskind notes Beelink moved to user-upgradeable DDR5 here.
- SER9, LPDDR5X-7500 (soldered): ~120 GB/s. The older machine's memory is faster (per Beelink's own SER9 spec).
- Strix Halo (Ryzen AI Max+ 395), LPDDR5X-8000, 256-bit: ~256 GB/s. Nearly 3× the SER10.
Read that again: the new SER10 Max may trade away token-generation headroom versus the SER9 it replaces, because Beelink swapped fast soldered LPDDR5X for slower upgradeable DDR5. A commenter (@taggerung890) spotted it instantly, "5600 vs 8000 on the 395 Max+." It's a real trade: you gain upgradeable, cheaper RAM and capacity; you give up the one spec that most governs LLM speed. For 7–14B models at Q4 that's fine. For anything bigger, the bandwidth wall, not the core count, is what you'll hit.
So which one should you buy?
Ziskind frames it as three machines, and that's the right framing:
- Want a small, quiet dev box that also dabbles in local AI? The SER10 Max is a fine pick, just budget the 10 minutes to enable Vulkan, and treat it as a 7–14B machine.
- Value-shopping? The SER9 is usually a couple hundred dollars cheaper, has the same 890M iGPU, and, thanks to its faster soldered memory, may match or beat the SER10 at token generation. Used units turn up on eBay too.
- Doing serious CPU/compile work or living in macOS? The M4 Pro Mac mini still leads single-core and IO-heavy builds, with a genuine ~22,400 multi-core, but a 1 TB / more-RAM config runs ~$2,000+ and Apple's memory pricing is brutal.
- buying this to run big local models? Save for a real Strix Halo box. The r/LocalLLaMA consensus, as aggregated buyer guides note, has largely settled on the 128 GB Ryzen AI Max+ 395 minis, like the GMKtec EVO-X2, for capacity-per-dollar. We cover those in our Strix Halo vs DGX Spark and Framework Desktop guides.
What viewers and owners are saying
The comment section under Ziskind's video skews skeptical, which, for a flat-ish refresh, is fair. The loudest themes:
- Test real models, not toys: "benchmarks of models and context sizes that people are using… who's using a 7b model on one of these machines?", @mrhappy678 on YouTube. (Reasonable; though 7–14B is genuinely what a 890M box is for.)
- The bandwidth catch: "wait the ser10 doesn't use high speed RAM? 5600mt/s vs the 8000mt/s on the 395 max+?", @taggerung890 on YouTube.
- The Geekbench correction above, from @charlievarley.
- "I'd rather wait for the big one": "Patiently waiting for the 495+ with 192GB RAM…", @TotusEius on YouTube, i.e. the Strix Halo successor, again underscoring that this isn't that chip.
- One genuinely useful pro-tip on the AMD/Vulkan path: "using Vulkan, you can combine dissimilar GPUs. I'm running a 16 gig RTX and a 16 GB Radeon, Gemma 31B, 128K context, entirely on GPUs.", @MichaelRainabbaRichardson on YouTube.
On the price grumbling ("in 2024 I bought my GMKtec Ryzen 9 7940HS 32GB for $700; now something similar is $1,300", @Ahamshep), they're not wrong, the 2025–26 memory crunch pushed this whole mini-PC class up, which is exactly why the SER9's value case is stronger than usual.
Sources & how we researched this
We have not tested a SER10 Max first-hand; this piece summarizes Alex Ziskind's "AMD's Strix Successor Just Caught the M4 Pro" (we skipped the sponsor segment) and cross-checks his findings against primary sources: AMD's HX 470 spec page and Gorgon Point coverage for the chip; Geekbench Browser for the corrected M4 Pro scores; the llama.cpp Vulkan discussion and AMD GAIA issue #1295 for the "CPU-by-default" behavior; AMD's Lemonade playbook for the NPU+iGPU hybrid path; and Beelink's SER9 LLM notes for the memory spec. Tokens/sec are Ziskind's measured figures; treat single-run numbers as directional, not gospel.
Related guides
- Strix Halo vs DGX Spark: Running 70B Locally, According to People Who Own Both
- Framework Desktop Buyer's Guide: The Repairable Strix Halo Box
- Can I run it?, check which models fit your machine · Quant picker
Bottom line: the SER10 Max is a solid little Windows dev box that, with one flag flipped, makes a perfectly good 7–14B local-AI machine. Just don't let the "caught the M4 Pro" headline talk you into it as a heavy-compile or big-model workhorse, on multi-core it isn't, and on the spec that matters most for LLM speed, memory bandwidth, it's a step behind both its own predecessor and the Strix Halo boxes the local-AI crowd reaches for.