The DGX Spark is one of the most argued-about pieces of AI hardware on the internet. Scroll Reddit and you'll find both camps loudly represented. But underneath the noise, a specific kind of owner keeps showing up in the threads, researchers, students, founders, and homelab builders who bought the little gold box, put it to work, and quietly fell for it. This post compiles what those owners say, in their own words, with links back to every thread, so you can decide whether you're the person it's built for.
A note on sourcing: these are real, attributed quotes from public Reddit threads (mostly r/LocalLLaMA, plus r/nvidia, r/homelab, and r/aiagents). The Spark also has vocal critics, we link to them at the bottom so you get the full picture, not just the highlight reel.

🧮 Not sure your machine can run the models discussed here? Check it in our calculator →
"An AI Lab in a Box", Especially If You Don't Have a Data Center
The most compelling praise doesn't come from benchmark-chasers. It comes from people who simply couldn't do their work before. In a thread titled "DGX Spark: an unpopular opinion" (820+ upvotes), a doctoral student in a small research group laid it out plainly:
"We only have a handful of V100s and T4s in our local cluster, and limited access to A100s and L40s on the university cluster (two at a time). Spark lets us prototype and train foundation models, and (at last) compete with groups that have access to high performance GPUs like the H100s or H200s.", u/emdblc, r/LocalLLaMA
Crucially, this is a clear-eyed fan, not a hype man:
"I want to be clear: Spark is NOT faster than an H100 (or even a 5090). But its all-in-one design and its massive amount of memory (all sitting on your desk) enable us, a small group with limited funding, to do more research.", u/emdblc, r/LocalLLaMA
That's the recurring theme across the positive threads: the Spark isn't trying to win a drag race. It's trying to put a full, coherent AI development environment on your desk, and for the people who need exactly that, it lands.
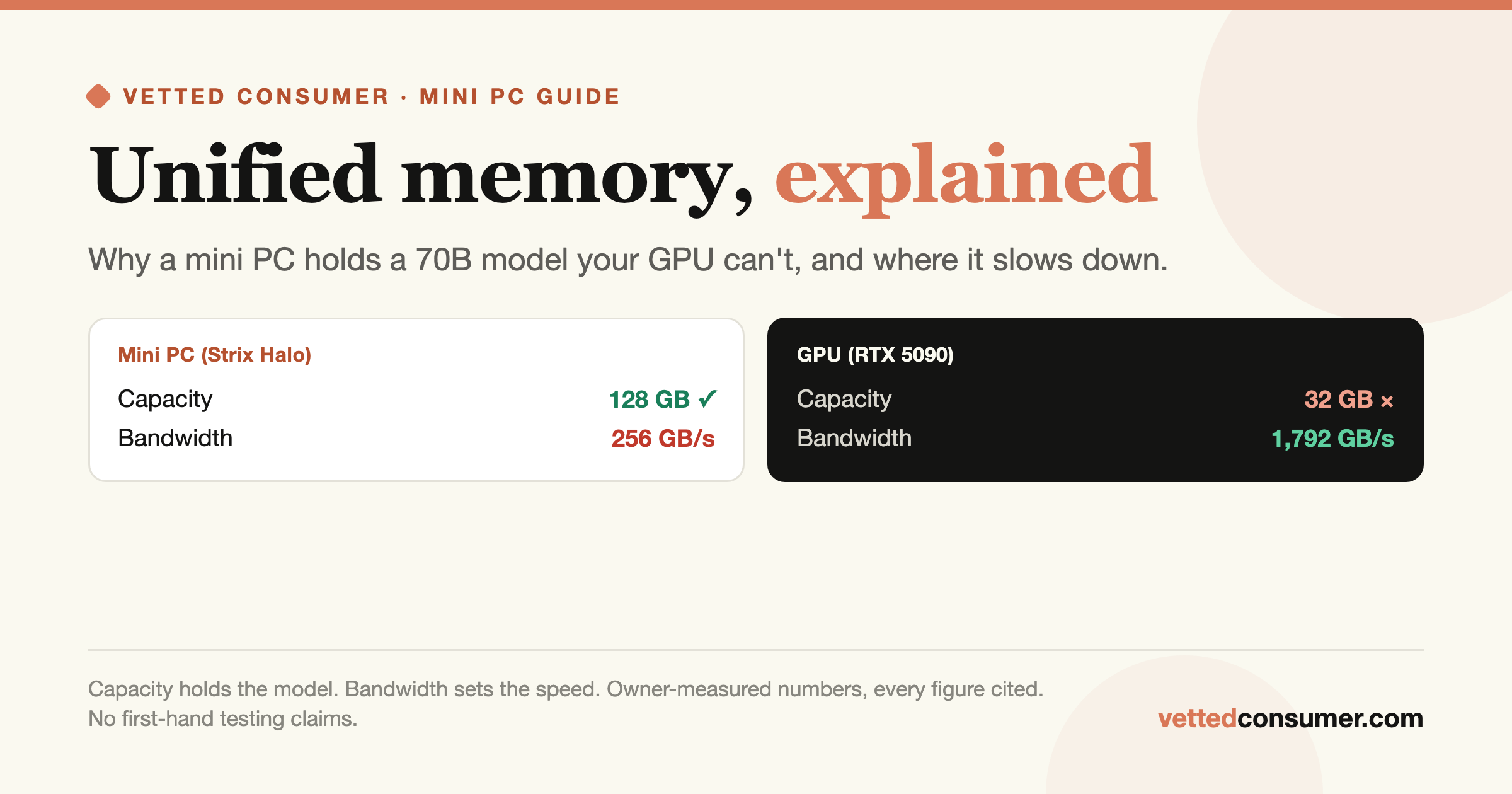
128GB of Unified Memory: Run the Models Other Desktops Can't
The headline capability is memory. The Spark's 128GB of coherent unified memory is what lets it load models that simply won't fit on a typical desktop GPU. In an "ask me anything" thread the day the device shipped, an owner walked through running GPT-OSS-120B locally:
"GPT-OSS-120B, medium reasoning… Answer quality was excellent, with a pro/con table for each webtech, an architecture diagram, and code examples. Was able to max out context length to 131072.", u/sotech117, r/LocalLLaMA
He was candid about the trade-off (it's not the fastest tokens/sec on the market), but landed on a clean summary of who it's for:
"If you need a large amount of Cuda VRAM (100+GB) just to get NVIDIA-dominated workflows running, this product is for you.", u/sotech117, r/LocalLLaMA
That capacity is exactly why the most ambitious owners on Reddit keep buying more of them. One homelab builder assembled a 16-unit cluster and explained the logic in a single word:
"Why this over H100s or a GB300? Unified memory. The whole point is maximizing unified memory capacity within the Nvidia ecosystem. With 8 nodes I was serving GLM-5.1-NVFP4 (434GB).", u/Kurcide, r/homelab

The CUDA Advantage: The Whole Ecosystem Just Works
This is the quiet superpower experienced developers single out. The Spark runs NVIDIA's full native stack, CUDA, the vLLM kernels, the open-source tooling, the same platform you deploy to in the cloud. In a detailed three-day head-to-head against a Mac Studio M3 Ultra, one owner put it bluntly:
"CUDA tensor cores, vLLM kernels, tensor parallelism… The entire open source GPU ecosystem just works. Batch embedding that takes days on MLX finishes in hours on CUDA.", u/trevorbg, r/LocalLLaMA
It's also why the platform rewards tinkerers. NVIDIA officially supports clustering two Sparks; one developer wanted three, wrote a custom 1,500-line NCCL networking plugin, and got there anyway:
"The result: Distributed inference across all 3 nodes at 8+ GB/s over RDMA… it works.", u/Ok-Pomegranate1314, r/LocalLLaMA (919+ upvotes)
It Pays for Itself, and Keeps Your Data Yours
For anyone running models around the clock, the economics flip fast. The same Mac-vs-Spark reviewer did the math after a painful run of cloud bills:
"$2K/month API spend. $20K total hardware. 10 months to break even. After that it is free inference forever with complete privacy and no rate limits.", u/trevorbg, r/LocalLLaMA
An AI-agents builder running models 24/7/365 made the privacy case even more directly:
"I spent a third of that yearly cost to buy these computers. I'll be able to use them for years for free. On top of that they're completely private, secure, and personalized. Not a single prompt goes to a cloud server that can be read by an employee or used to train another model.", u/Aislot, r/aiagents

Setup Is Smoother Than the Internet Led People to Expect
A common worry with first-gen hardware is a painful out-of-box experience. Owners report the opposite. The Spark ships with NVIDIA's flavor of Ubuntu and the AI stack pre-loaded:
"Setup of the Sparks was time consuming but honestly smoother than I expected. Each Spark runs Nvidia's flavor of Ubuntu out of the box with mostly everything pre installed and ready to go.", u/Kurcide, r/homelab
"Things like docker, git, and python are setup for you too. Makes it quick and easy to get going.", u/sotech117, r/LocalLLaMA
A Community That Refuses to Let It Fail
One underrated reason to buy into a platform is the people already on it. In a thread praising the official DGX Spark developer forum, a master's student described an unusually generous, tenacious community squeezing every drop of performance out of the hardware:
"The people in the DGX forum community are some of the kindest, smartest, most tenacious group of developers I've met… I bought one because I'm pursuing a Masters in AI and I wanted it for training models, tool dev, testing, etc.", u/Porespellar, r/LocalLLaMA
That energy shows up everywhere the device lands, including offices, where a simple "Just received this little guy at our office" post pulled nearly a thousand upvotes from people who clearly wanted one too (u/dupontcyborg, r/nvidia).

Even the Skeptics Love How It Looks
Here's a tell: in a thread literally titled "Disappointed by dgx spark," the critic still opened with this:
"gorgeous golden glow, feels like gpu royalty.", u/RockstarVP, r/LocalLLaMA
When the people complaining about a product still compliment its design, you know the industrial design did its job. The Spark is a roughly 1.1-litre gold Founders Edition box that disappears behind a monitor and looks like a piece of jewelry next to a laptop.
Who Should Buy One (And Who Shouldn't)
The owners themselves are refreshingly blunt, so we'll be too. Buy a DGX Spark if you want:
- The largest local model capacity in a desktop form factor, 128GB of unified memory that runs models other desktops can't load at all.
- NVIDIA's full CUDA stack natively, so your code, containers, and skills transfer straight to cloud and production hardware.
- A complete, ready-to-build "AI lab in a box" for fine-tuning, RAG, agents, and multi-model workflows, not a benchmark trophy.
- Privacy and predictable cost for always-on local inference that pays for itself versus cloud APIs.
- A quiet, beautifully built machine backed by an unusually committed developer community.
Related buyer’s guides
- ASUS ROG Ally X20: The OLED Handheld Fans Wanted, With Two Catches
- AMD's RX 9070 GRE: Reviewers and Reddit Agree, Skip It
- Panther Lake's First Mini PC: Wendell Tests the MSI Cubi NUC AI+ (and What Owners Think)
Be real with yourself if your only goal is the cheapest, fastest tokens-per-second. As owners and critics alike note, a maxed-out M5 Mac or a multi-GPU rig can beat the Spark on raw single-stream speed because of higher memory bandwidth. The Spark's value is capacity, ecosystem, and coherence, not peak throughput. If that's the trade you want to make, the people who made it keep saying the same thing:
"its all-in-one design and its massive amount of memory (all sitting on your desk) enable us… to do more research.", u/emdblc, r/LocalLLaMA
Sources & Further Reading
Every quote above is from a public Reddit thread. For balance, we've also linked the most prominent critical threads, read both sides before you spend the money.
Positive / owner threads:
- DGX Spark: an unpopular opinion, u/emdblc, r/LocalLLaMA
- Got the DGX Spark, ask me anything, u/sotech117, r/LocalLLaMA
- Dual DGX Sparks vs Mac Studio M3 Ultra 512GB, u/trevorbg, r/LocalLLaMA
- Added a 16x DGX Spark cluster to my Homelab, u/Kurcide, r/homelab
- I clustered 3 DGX Sparks that NVIDIA said couldn't be clustered, u/Ok-Pomegranate1314, r/LocalLLaMA
- Running local models 24/7 vs frontier API costs, u/Aislot, r/aiagents
- The DGX Spark Forum community of devs is talented AF, u/Porespellar, r/LocalLLaMA
- Just received this little guy at our office, u/dupontcyborg, r/nvidia
Critical threads (for balance):