Spend around $10,000 on a local-AI machine and you face a genuine fork: a Mac Studio M3 Ultra (512 GB) or a dual NVIDIA DGX Spark setup. Same money, completely different philosophies, Apple's enormous, fast unified memory versus NVIDIA's CUDA compute and clustering. One r/LocalLLaMA owner bought both and ran the same 397-billion-parameter model on each, so instead of theorizing, here's what people who own these machines measured.

🧮 Not sure your machine can run the models discussed here? Check it in our calculator →
The matchup
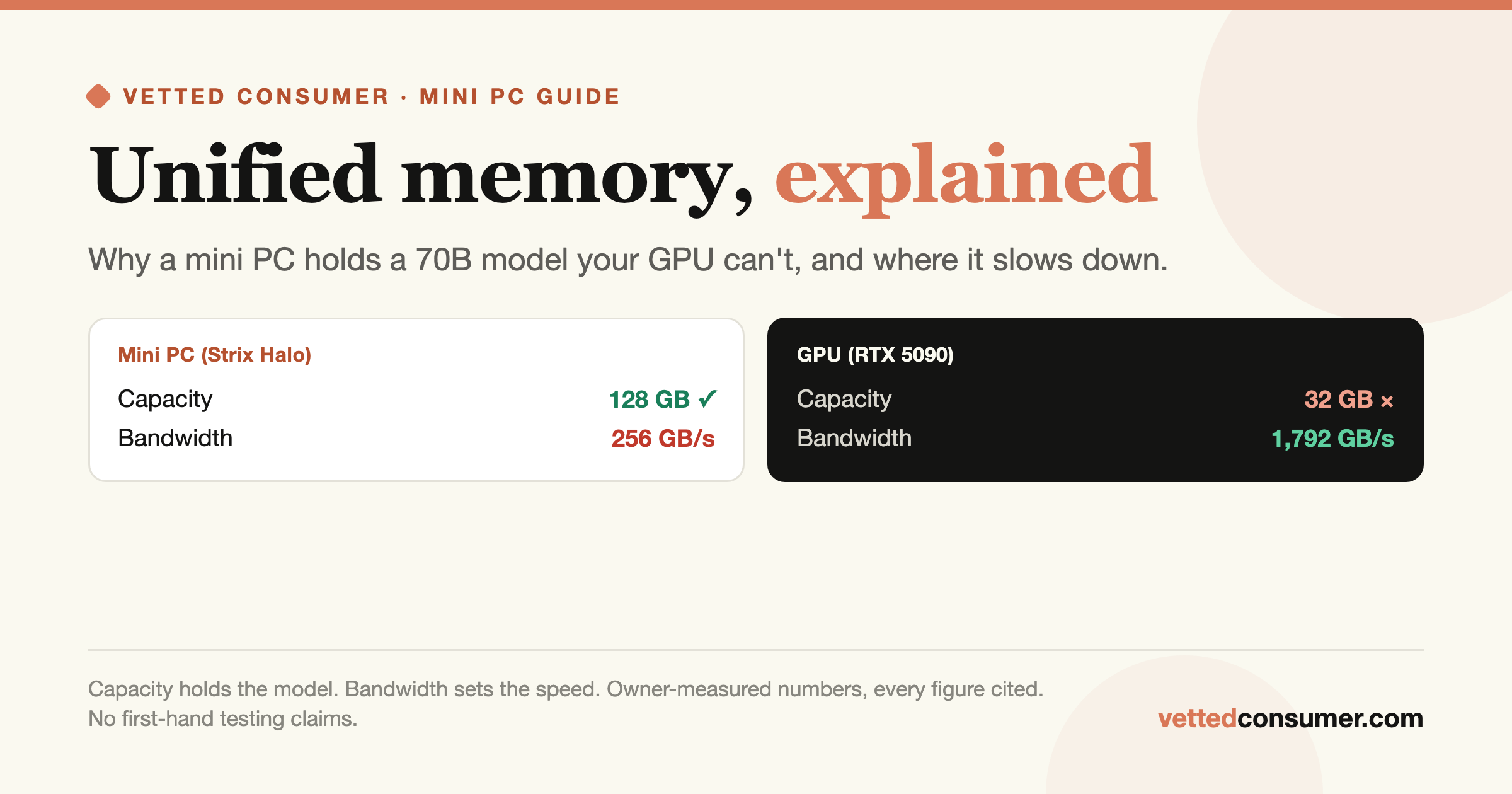
The Mac Studio M3 Ultra tops out at 512 GB of unified memory with roughly 800 GB/s of bandwidth, the headline number for local LLMs, because bandwidth is what makes token generation feel smooth on a giant model. The DGX Spark is capped at 128 GB per unit, but two of them cluster over a 200 Gbps link and run the full CUDA/vLLM stack. Same ~$10K, opposite strengths.
Head-to-head: one owner ran 397B on both
The standout report is u/trevorbg's "Dual DGX Sparks vs Mac Studio M3 Ultra 512GB", after he got tired of spending ~$2K/month on cloud API and went local. Running Qwen3.5-397B (A17B) on each:
"Mac Studio (MLX 6-bit, 323GB model in 512GB unified): 30–40 tok/s generation. The biggest selling point is ~800 GB/s bandwidth, that's what makes generation feel smooth on such a massive model in a single box. The weakness is raw compute: prefill is slow (30+ seconds on a big system prompt with tool definitions).", u/trevorbg
"Dual Sparks (INT4, vLLM TP=2 across two 128GB nodes): 27–28 tok/s generation. The biggest selling point is processing speed, CUDA tensor cores and vLLM.", u/trevorbg
One important caveat on these numbers: they aren't a clean apples-to-apples comparison. The Mac Studio ran the model at MLX 6-bit while the dual Sparks ran INT4 (roughly 4-bit), so the Mac was doing more work per token at higher precision and still matched or beat the Sparks on generation. If anything, that makes the Mac's bandwidth advantage look stronger, not weaker, since a like-for-like quant would likely widen the gap in its favor. Treat the tok/s figures as directional rather than a controlled benchmark: the takeaway is the shape of the difference (Mac wins generation and capacity, Sparks win prompt processing), not the exact numbers.
So token generation is surprisingly close (Mac slightly ahead on a single box). The real split is prefill / prompt processing, the DGX setup's CUDA compute chews through long prompts, while the Mac's weakness, as another owner put it bluntly, is exactly that: "prompt processing is the Mac Studio's main limit on inference, problematic for large-document processing or agentic workflows" (u/Icy-Measurement8245).
The catches owners flag
Two real caveats. On the Mac side, it's not turnkey for serious agent work, trevorbg had to "write a 500-line async proxy because MLX-VLM doesn't parse tool calls or strip thinking tokens natively." On the NVIDIA side, the DGX Spark draws skepticism as a consumer buy: "this isn't a consumer inference machine," wrote u/Cautious-Raccoon-364, who uses them professionally, "its main benefit is the memory and NVIDIA's enterprise software; we use them for rapid prototyping, then take it to our AI factory for actual training." And the value crowd is harsh: a popular thread literally argued the DGX Spark is "a bad 4K investment vs a Mac" for personal use.
Who should buy which
Buy the Mac Studio M3 Ultra if you want to run the largest models in a single quiet box, you value memory capacity and bandwidth (512 GB is unmatched here), your prompts are short-to-medium, and you're comfortable in the MLX/Apple-Silicon world. Buy DGX Spark(s) if you need fast prompt processing for long-context or agentic workloads, you're committed to CUDA and want vLLM/TRT to "just work," or you'll cluster nodes and later scale to bigger NVIDIA hardware. Note that, per owners, NVIDIA later raised the Spark's price and dropped the top Mac config to 256GB, so check current pricing before deciding.
The bottom line
At the same ~$10K, the choice is capacity-and-bandwidth (Mac) versus compute-and-CUDA (DGX). For most people running big models at home, the Mac Studio M3 Ultra is the simpler, higher-capacity pick, just budget for slow prefill and some MLX tinkering. The DGX route wins for CUDA-bound, long-context, or multi-node workflows where prompt processing and the NVIDIA software stack are worth the friction.
Sources & how we researched this
We have not tested these machines first-hand, this aggregates real owner reports and owner-run benchmarks, linked so you can verify, prioritizing people who own both and including critical threads for balance. Note: the owner’s two systems used different quantizations (MLX 6-bit vs INT4), so the benchmarks are directional, not controlled.
- u/trevorbg, "Dual DGX Sparks vs Mac Studio M3 Ultra 512GB: Running Qwen3.5 397B on both" (owns both; tok/s benchmarks)
- u/Icy-Measurement8245 & others, "Why choose DGX Spark over Framework Desktop or Mac Studio?" (Mac prompt-processing limit)
- u/meshreplacer / u/Cautious-Raccoon-364, "DGX Spark a bad 4K investment vs Mac" (critical, for balance)
Related guides
- Mac Studio M3 Ultra: the local-AI workhorse
- The NVIDIA DGX Spark, According to the People Who Own One
- Is the RTX Spark a "marketing trap"?